osm-edge は、必須のサービス メッシュ機能をすべて提供しながら、高性能なサービス メッシュを作成することを目指しています。 このドキュメントでは、osm-edge のパフォーマンスとスケーラビリティを評価するために実行されたテストについて説明します。
テスト環境
このテストは、Microsoft Azure Kubernetes Service によってプロビジョニングおよび管理される Kubernetes クラスターで実行されます。 クラスターには 100 個の Standard_DS2_v2 ノードがあります (各ノードには 2 つの vCPU と 7 GB のメモリがあります)。 テスト中に、デフォルトのリソース クォータで実行されている osm-edge コントローラー ポッドが 1 つだけ存在することが保証されます。 osm-edge は非許容トラフィック モードで構成されます。
過程
テスト メッシュには 2 種類のサービスが含まれています。 1 つはロード ジェネレーター (wrk2 から変更) で、指定されたレートでリクエストを送信し、メッシュ内の他のすべてのサービス間で負荷分散を行うことができます。 現在、HTTP 1 リクエストのみをテストしています。 Load Generator は、リクエストのクライアント側として機能します。 テスト全体を通して、負荷生成サービスは最大で 1 つです。 インバウンド要求から受信するものは何でも。要求のサーバー側として機能します。メッシュにエコー アプリケーションの複数のコピーを展開できます。要するに、メッシュ トポロジは典型的な 1 対 N サービス アーキテクチャです。
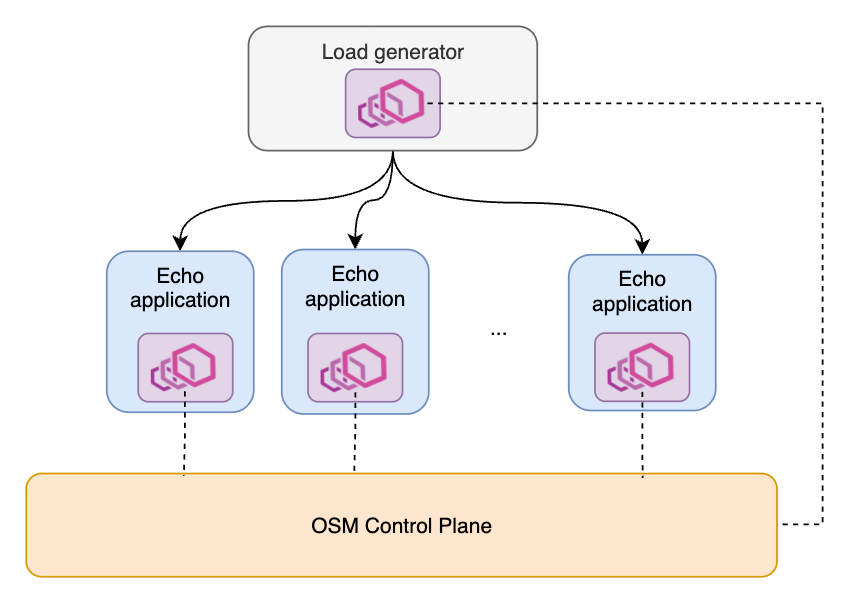
パフォーマンス
このテストでは、osm-edge サイドカーによって追加されるレイテンシ オーバーヘッドとリソース消費に注目します。 現在、ポッドごとの RPS をそれぞれ 100、500、1000、2000、4000 でテストしています。
レイテンシー
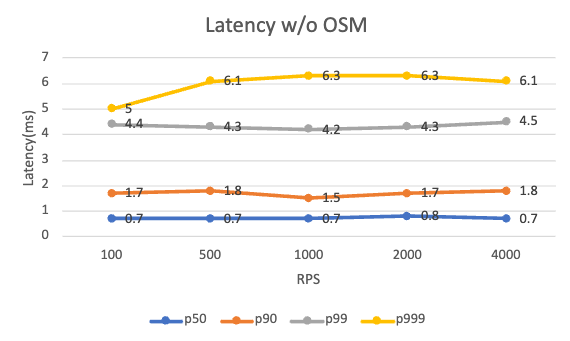
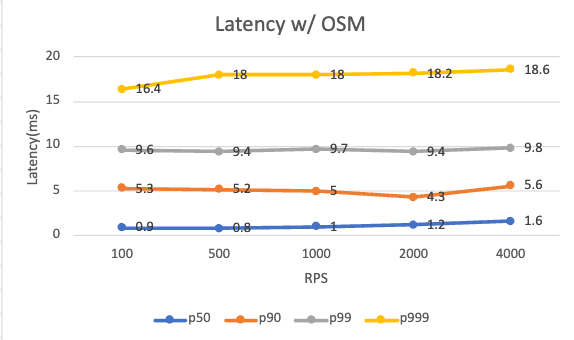
以下は、osm-edge がインストールされている場合とインストールされていない場合の、さまざまな RPS レベルでのリクエスト レイテンシです。 追加のレイテンシーは、クライアントとサーバーの両方のサイドカーから発生します。
| Per pod RPS | 100 | 500 | 1000 | 2000 | 4000 |
|---|---|---|---|---|---|
| P99 latency w/o osm-edge (ms) | 4.4 | 4.3 | 4.2 | 4.3 | 4.5 |
| P99 latency w/ osm-edge (ms) | 9.6 | 9.4 | 9.7 | 9.4 | 9.8 |
osm-edge の存在に関係なく、アプリケーションは、テストされたさまざまな RPS レベルでほぼ同じように動作します。 osm-edge は、99 パーセンタイルのレイテンシで約 5 ミリ秒のオーバーヘッドを追加します。 テストのセットアップは非常に単純で、単一のクライアント/サーバー関係があることに注意してください。 走行距離は、より複雑なアプリケーションや、メッシュに設定されたさまざまなトラフィック ポリシーによって異なる場合があります。
リソース消費
コントロール プレーンのリソース消費は、データ プレーンのリクエスト レートとは無関係であるため、安定しています。
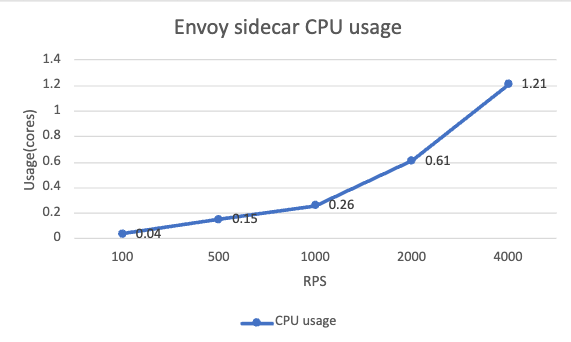
データ プレーンのサイドカーの場合、メモリ使用量はさまざまな RPS レベルで比較的一貫しており、約 140MB です。 CPU 使用率は明らかに増加傾向にあり、RPS レベルにほぼ比例しています。 私たちの場合、60 ミリコアのベースライン CPU を使用すると、サイドカーの CPU 消費は 100 RPS ごとに約 0.1 コアずつ直線的に増加します。
スケーラビリティ
スケーラビリティ テストでは、メッシュ内のワークロード数が増加するにつれて、コントロール プレーンとデータ プレーンの両方のリソース消費がどのように変化するかを調べます。 指定された数のエコー サービスがメッシュに同時に展開されます。 したがって、コントロール プレーンは、デプロイの開始後に負荷スパイクを受け取ります。 すべての Pipy サイドカーが同時にコントロール プレーンに接続しています。 その後、コントロール プレーンはさらにアイドル状態になります。 メッシュが処理できる最大スケールを確認するために、Pod のロールアウト時にこの負荷スパイクを意図的に作成します。 テストの各ラウンドは 15 分間続きます。 200、400、800、および 1600 ポッドのメッシュ スケールがそれぞれテストされます。 Load Generator サービスは、スケーラビリティ テストでは使用されません。
コントロール プレーン
CPU使用率
以下は、ポッドのロールアウト時と安定時の両方でのコントロール プレーンの CPU 使用率を示しています。
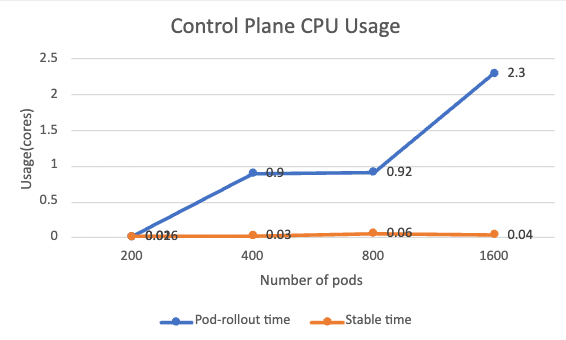
ポッドのロールアウト時間の CPU 使用率には、明確な増加傾向があります。 コントロール プレーンは、証明書の発行や xDS 構成の生成など、すべてのワークロードを同時に処理するため、これは理解できます。 CPU 使用率は、ワークロードの数にほぼ比例します。 新しいワークロードが追加されない安定した時間の間、CPU 使用率はほぼゼロに低下します。
メモリ使用量
以下は、ポッドのロールアウト時と安定時の両方でのメモリ使用量を示しています。
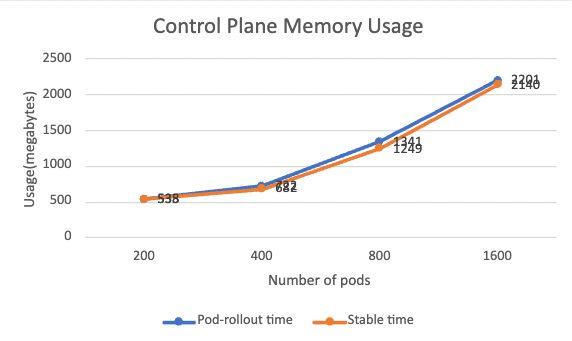
メモリ使用量に関しては、ポッドのロールアウト時間と安定時間の間に大きな違いはありません。 メモリは主に、メッシュ スケールとの関連性が高い xDS 構成を格納するために使用されます。 メモリ使用量も、メッシュ スケールにほぼ比例して増加しています。 このシナリオでは、メッシュにポッドを 1 つ追加するごとに約 1MB のメモリが必要です。
データプレーン
収集されたメトリクスを見ると、私たちのテスト シナリオでは、データ プレーン サイドカーのリソース消費はメッシュ サイズによってあまり変化しません。 安定時の平均 CPU 使用率は 0 に近く、平均メモリ使用率は約 50MB です。 CPU 使用率はリクエスト処理に関連し、メモリ使用量はローカルに保存されている Pipy 構成のサイズに関連しています。 これら 2 つの要因は、メッシュ スケールによって変化しません。
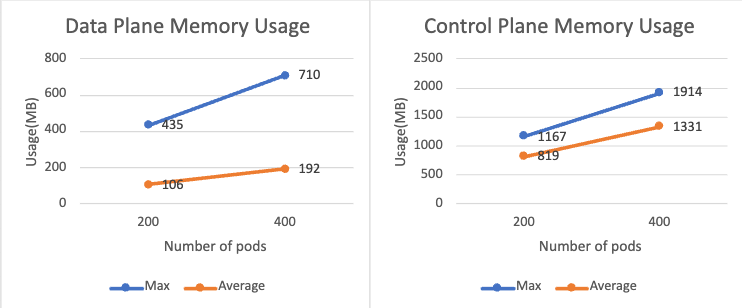
permissive モードを有効にすると、各サイドカーが他のすべてのサービス間の接続構成を維持する必要があるため、データ プレーンがより多くのメモリを使用することにも言及する価値があります。 以下のグラフは、permissive モードが有効なメッシュに 200 個と 400 個の Pod が追加された場合のサイドカーのメモリ使用量を示しています。 非許容モードと比較すると、メモリ使用量は 2 倍以上になります。 同様のことがコントロール プレーンでも発生します。
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.